








昨日できなかったけど、
今日で、ようやくPython講座も終わり!
これで、初級の講座全て終わった――。
明日スタートテスト受けれるかな。
■AIを学ぶ為の本格Python講座
PY25_scikit-learnの基礎といろいろな機械学習モデルの使用
今日学んだこと
scikit-learnとは
様々な機械学習のアルゴリズムに対して、アルゴリズムの中身をあまり分からなくても
書き方さえ学べばアルゴリズムを使用できるようなっているライブラリ
scikit-learnの使い方
irisというデータセットでscikit-learnを試してみる。
irisはアヤメという花の3つの品種について、計測したデータを纏めたもの
irisはscikit-learnのライブライりにデータが付属している。
機械学習のデータは、
訓練用データと検証用データに分けて、モデルを学習させる。
訓練用は実際に学習で使うデータで、学習させた後、
検証用データで、実際に動作を確認する。
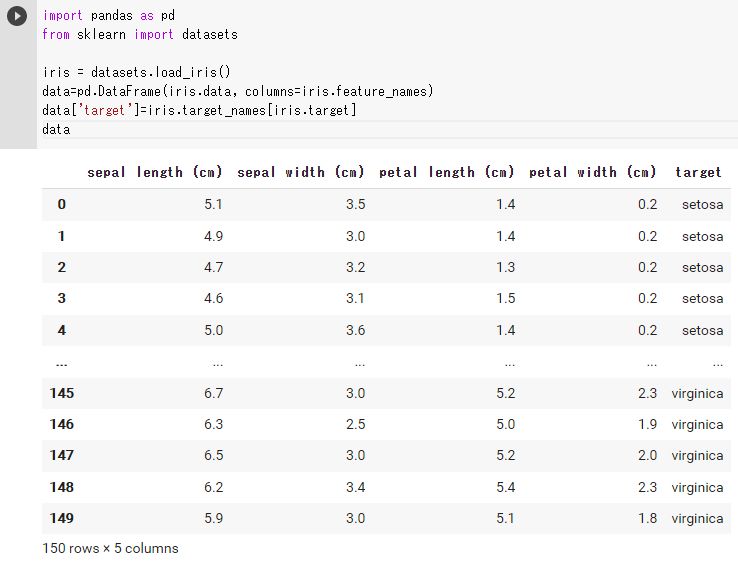
まずデータを準備する。
import pandas as pd
from sklearn import datasets
iris = datasets.load_iris()
data=pd.DataFrame(iris.data, columns=iris.feature_names)
data['target']=iris.target_names[iris.target]
data
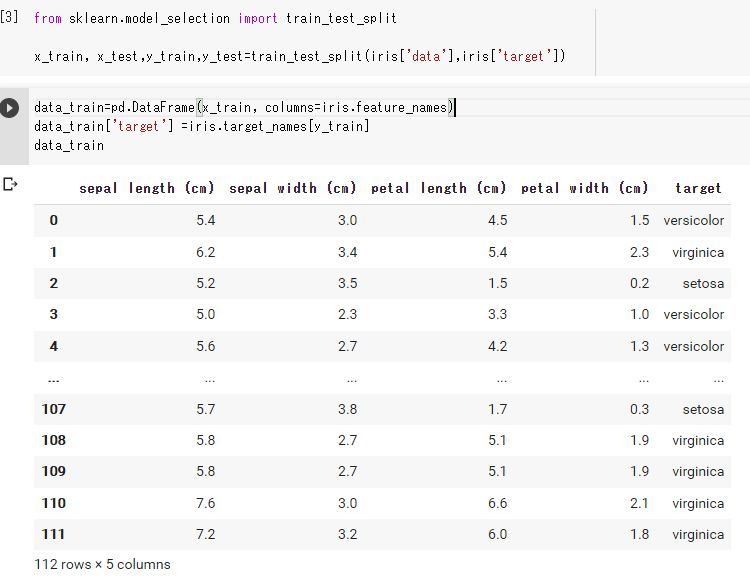
訓練用データと検証用データを分ける。
sciket-learnのtrain_test_split を使う。
訓練用データと検証用データを75%、25%に分ける。
from sklearn.model_selection import train_test_split
x_train, x_test,y_train,y_test=train_test_split(iris['data'],iris['target'])
元の150データの75%、112件の訓練用データが確認できる。
targetの列はもともと、きれいに並んでいたけど、ばらばらになっている。
同じ種類のデータを連続で学習しないようランダムに並べている。
data_train=pd.DataFrame(x_train, columns=iris.feature_names)
data_train['target'] =iris.target_names[y_train]
data_train
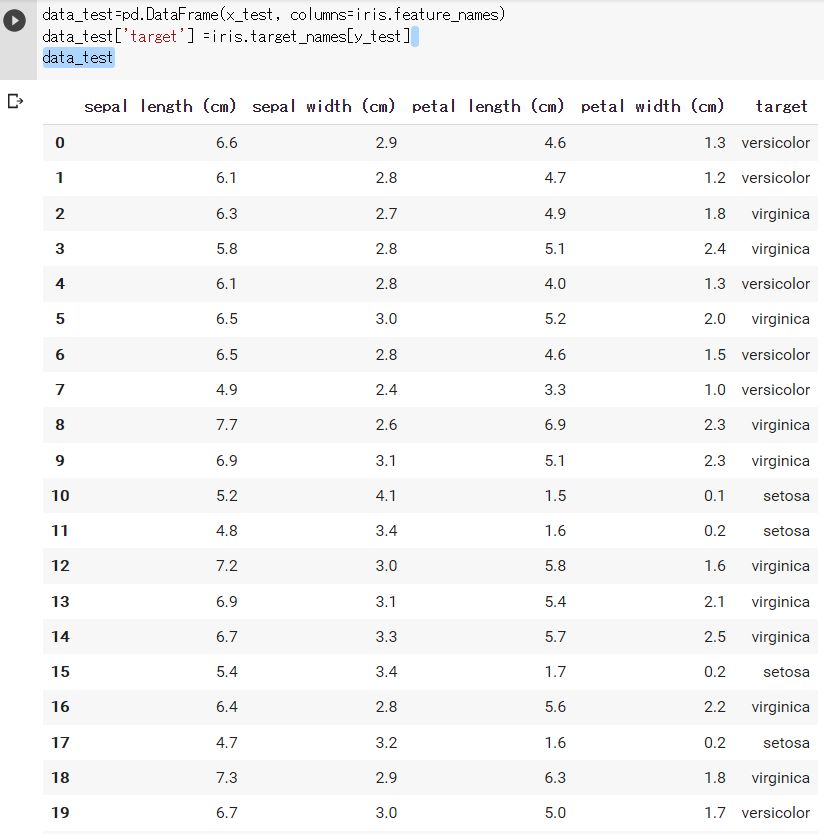
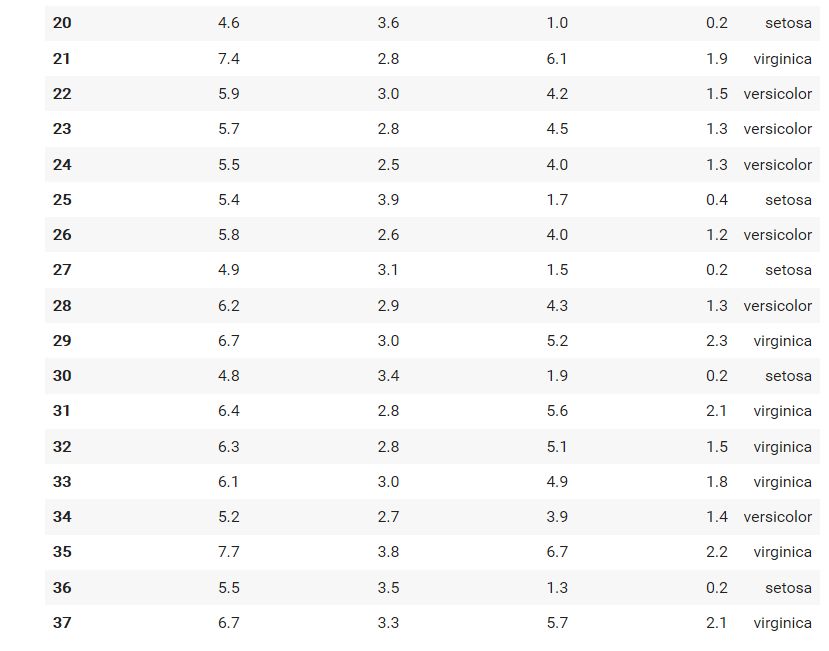
次に検証用データを確認する。
約25%の37件を確認できる。
これでデータの準備は完了。
K-近傍法をscikit-learnで使ってみる。
scikit-learnは、fit関数にデータを渡すことで学習できる。
from sklearn.neighbors import KNeighborsClassifier
アルゴリズムを準備する。
knn=KNeighborsClassifier(n_neighbors=1)
学習データをfitに渡す。
knn.fit(x_train, y_train)

学習のあと、predict関数で、学習結果を使用して、推論を行うことができる。
検証用データの1つ目のデータについて推論を試す。
データをpredict関数に渡すときは、レコードを必ず配列の中に入れて渡す必要がある。
predicted=knn.predict([x_test[0]])
predicted
⇒
array([1])
推論の結果の1の意味を調べる。
predictで出てきた結果は分類結果を数値で表現したもの。
irisデータセットではこの数値による分類結果を文字列に戻すことで
分類結果を確認できる。
結果は、versicolor だった。
iris['target_names'][predicted]
⇒
array(['versicolor'], dtype='<U10')
検証用データには正しい情報があり、比較してみる。
結果は、versicolor と表示され、k-近傍法による分類は、あっていることが分かる。
iris['target_names'][y_test[0]]
⇒
versicolor
scikit-learnの学習のまとめ
データセットを用意する。
データセットを訓練用データと検証用データに分ける。
アルゴリズムを準備する。
学習データをfitに渡す。
predict関数で推論する。
数値の分析結果を文字列で確認する(irisデータセットの場合)
検証用データの答えと比較する。
単回帰モデルの使用
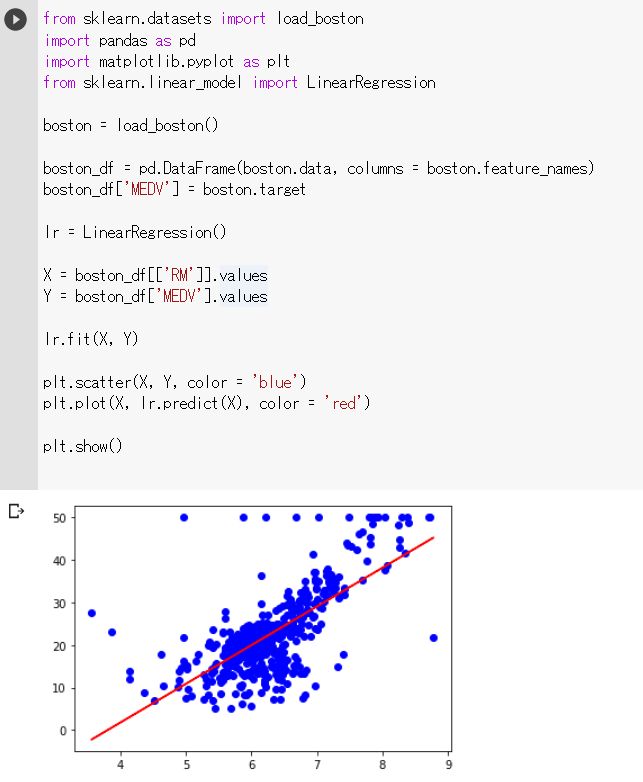
ボストン住宅価格のデータセットを使って、単回帰モデルを確認する。
from sklearn.datasets import load_boston
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
boston = load_boston()
boston_df = pd.DataFrame(boston.data, columns = boston.feature_names)
boston_df['MEDV'] = boston.target
アルゴリズムを準備(単回帰 リニアレグレション)
lr = LinearRegression()
X = boston_df[['RM']].values
Y = boston_df['MEDV'].values
fitで学習する。
lr.fit(X, Y)
plt.scatter(X, Y, color = 'blue')
predictで結果を表示
plt.plot(X, lr.predict(X), color = 'red')
plt.show()
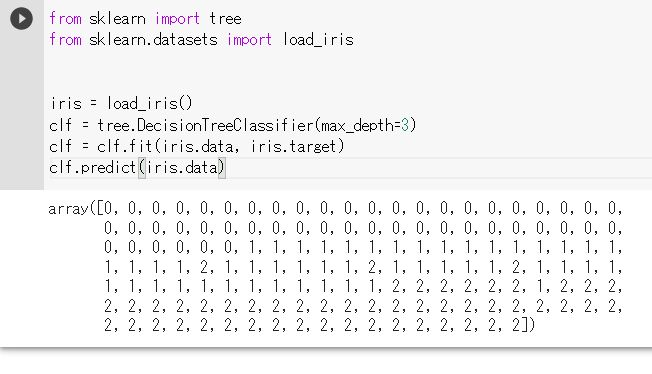
決定木(けっていぎ)
分類のアルゴリズム
from sklearn import tree
from sklearn.datasets import load_iris
iris = load_iris()
アルゴリズムを準備
clf = tree.DecisionTreeClassifier(max_depth=3)
学習する。
clf = clf.fit(iris.data, iris.target)
推論を出力
clf.predict(iris.data)
サポートベクタ―マシン
分類のアルゴリズム
from sklearn import svm
from sklearn.datasets import load_iris
iris = load_iris()
アルゴリズムを準備
clf = svm.SVC(gamma="scale")
学習する
clf = clf.fit(iris.data, iris.target)
結果を表示
clf.predict(iris.data)

勉強時間
今日: 1.0時間
総勉強時間: 37.0時間
お得キャンペーンの紹介
ラビットチャレンジの
Amazonギフト券「5,000円」プレゼントキャンペーンのお知らせ
申込時に、以下コードを使えば、入会金が5000円引かれるようです。
また、紹介した僕にも5000円のAmazonギフト券が送られるようです。
お得なので、よかったら申込時お使いください。
紹介コード:friend0019697
※本キャンペーンの期間は、 2021年9月15日~10月31日 です。
「お友達紹介キャンペーン」特設ページ:
https://ai99