

さくらのVPSじゃないけど、Windows上でrubyでブラウザ操作ができるseleniumを試した。
サイトにアクセスして、そのサイトのすべてのリンクをクリックして、リンク先のスクリーンショットを撮る という動作が自動でできた。
洗練されれば、windowsサーバの設定のエビデンスが自動で残せるかも。
また、書いてはないけど、結構簡単に、さくらのVPSのコントロールパネルにログインして、サーバを起動できた。
参考)windowsならruby + selenium webdriverも環境設定は15分で終わる
http://katsulog.tech/if-windows-ruby-selenium-webdriver-also-ending-the-configuration-in-15-minutes/
参考)Webブラウザの自動操作 (Selenium with Rubyの実例集)
https://www.qoosky.io/techs/71dd2d67ea
PCの環境
OS
Windows10 HOME
Ruby
ruby 2.4.4p296 (2018-03-28 revision 63013) [x64-mingw32]
ブラウザ
Chrome バージョン: 67.0.3396.99(Official Build) (64 ビット)
1.Seleniumの準備
Seleniumのインストール
gem install selenium-webdriver
たったこれだけ
Chrome Driverの設置
Chromeを操作するためのもの
https://sites.google.com/a/chromium.org/chromedriver/downloads
ここから最新のchromedriver win32.zipをダウンロード
解凍して、chromedriverというファイルを、C:\Ruby24-x64\binに保存する ※Ruby24-x64の部分は環境によって違うと思う
2.Seleniumの操作・関数まとめ
基本
require "selenium-webdriver" ⇒selenium-webdriver の呼び出し d = Selenium::WebDriver.for :chrome ⇒Chrome用のドライバを指定 d.navigate.to "file:///D:/rubyproject/data/selenium/link-text/index.html" ⇒指定したURLにアクセス
メソッド
d.page_source ⇒現在のページのソースを取得 submitElement = d.find_element(:name, 'commit') ⇒name属性にcommitが設定されている要素を取得 submitElement.click ⇒取得した要素をクリック d.find_element(:class, 'button') ⇒class名buttonの要素を取得 d.find_element(:class, 'button') ⇒elementsと複数形にすると、class名buttonの要素すべてを取得し、配列としてくれる。 d.current_url ⇒現在のページのURLを取得 d.save_screenshot "index.png" ⇒スクリーンショットを撮り、ファイル名index.pngとして保存する sleep(1) until driver.find_element(:id, 'main-contents').displayed? ⇒id名main-contentsが表示されるまで待機 未検証 e = d.find_element(:class, 'line').location_once_scrolled_into_view ⇒class名lineが表示されるまでスクロールする。 e = d.find_element(:xpath, '/html/body/a[100]').location_once_scrolled_into_view ⇒xpath指定で aタグの100番目の要素までスクロールする d.title ⇒ページのタイトルを取得 window.scroll(0,300); ⇒高さ300pxのところまですクロールする d.find_element(:tag_name, 'html').size.height ⇒HTML要素の高さを取得 element.send_keys "TEST-ID" ⇒値を送信する elementは要素を取得した変数
そのほか
配列を引数にする
ary = [:name, "f"] driver.find_element(*ary).submit()
JavaScriptのalert(), confirm(), prompt()で、ポップアップが表示される場合
#ダイアログボックスに制御を移す alert = d.switch_to.alert #はい、OKボタンをクリック alert.accept でOKをクリックできる。 ちなみに alert.text でポップアップの内容(テキスト)を取得できる。
フォーム入力参考
# name属性memberLogin[membercd]の要素を取得 form_id = d.find_element(:name, 'memberLogin[membercd]') #取得した要素にもともと文字が入っていたら削除して、IDを入力 form_id.clear form_id.send_keys "TEST-ID"

3.Seleniumのテスト
検証コードの内容
サイト(検証用で作成したリンクだらけのサイト)にアクセスし、リンクをクリックしてスクリーンショットを撮る
この操作をすべてのリンクで実行する。
検証サイト画面(このリンクは100 まである)

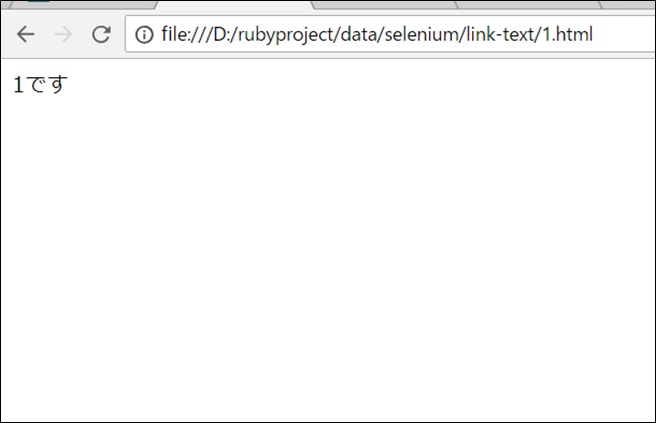
リンク先(「1です」をクリックしたとき)
★結果 最初に作成したコードではエラーで動かなかった
最初のページから移動して、戻る等で同じ最初のページに戻ってきたときには、
同じページなんだけど、find_elementで取得した値が違う!
すごい時間かかったけど、分かってよかった。。。
最初のコード
require "selenium-webdriver"
# Chrome用のドライバを指定
d = Selenium::WebDriver.for :chrome
# サイトにアクセス(サイトは検証用で作成したローカルファイル)
d.navigate.to "file:///D:/rubyproject/data/selenium/link-text/index.html"
sleep 2
#aタグの全要素を配列で取得し、その配列の各要素に対して処理を実行
a_elements=d.find_elements(:tag_name, 'a')
a_elements.each_with_index do |a,n|
#リンクをクリック
a.click
sleep 1
#リンク先のスクリーンショットを撮り、ファイル名a番号.pngとして保存する。ファイル名は1からにしたいので、n+1としている
d.save_screenshot "a#{n+1}.png"
#前のページに戻る
d.navigate.back
sleep 1
end
コード的には問題ないと思ったんだけど、エラーが出る。
ブロックの1回目は動くが2回目にエラーが出る。
エラー内容
C:/Ruby24-x64/lib/ruby/gems/2.4.0/gems/selenium-webdriver-3.13.0/lib/selenium/webdriver/remote/response.rb:69:in `assert_ok': stale element reference: element is not attached to the page document (Selenium::WebDriver::Error::StaleElementReferenceError)
頭に#をつけたり、けしたりして、試したところ、a.clickのところで、そんな要素ないよと言っているみたい。
中身がないのかなんと、puts aとしたらちゃんと中身はある。
結果、ページ遷移し、戻ってきたときには、a_elements=d.find_elements(:tag_name, 'a') の要素のIDが変わっていることに気づいた。
なので、要素は、最初のページに戻ってきたときに毎回再取得しないと思ったとおりの動作にならない。
#<Selenium::WebDriver::Element:0x74eceaea id="0.5025203954315989-3"> ページ遷移前のあるa要素のID #<Selenium::WebDriver::Element:0x3c74c216 id="0.5349117057642312-3"> ページ遷移し、戻ってきたときの同じa要素のID(find_elementで再取得後)
IDが違っていたから、そんな要素ないよっていってたみたい。
同じページなんだから同じにしといてほしい。なんか理由があるんだろうけど
あー疲れた。。。。
最終コード
毎回要素を取得するようにした。
無事動いてよかった。
require "selenium-webdriver"
# Chrome用のドライバを指定
d = Selenium::WebDriver.for :chrome
# サイトにアクセス
d.navigate.to "file:///D:/rubyproject/data/selenium/link-text/index.html"
sleep 2
i = 0
#リンク30個分のループ処理
while i < 30
#a要素すべてを配列で取得。これをループごとに毎回取得
a_elements=d.find_elements(:tag_name, 'a')
#aタグのテキスト部分を取得(どこまで進んでいるか確認する用)
puts a_elements[i].text
sleep 1
a_elements[i].click
sleep 2
#リンク先のスクリーンショットを撮り、ファイル名は番号.pngとして保存する。ファイル名は1からにしたいので、n+1としている
d.save_screenshot "#{i+1}.png"
sleep 1
#前のページに戻る
d.navigate.back
sleep 2
i += 1
end
selenium便利だ
あとxpathというものを知った。
これすごい便利。
要素を指定する場合、HTMLのクラス名や、タグ名を調べる必要があるけど、
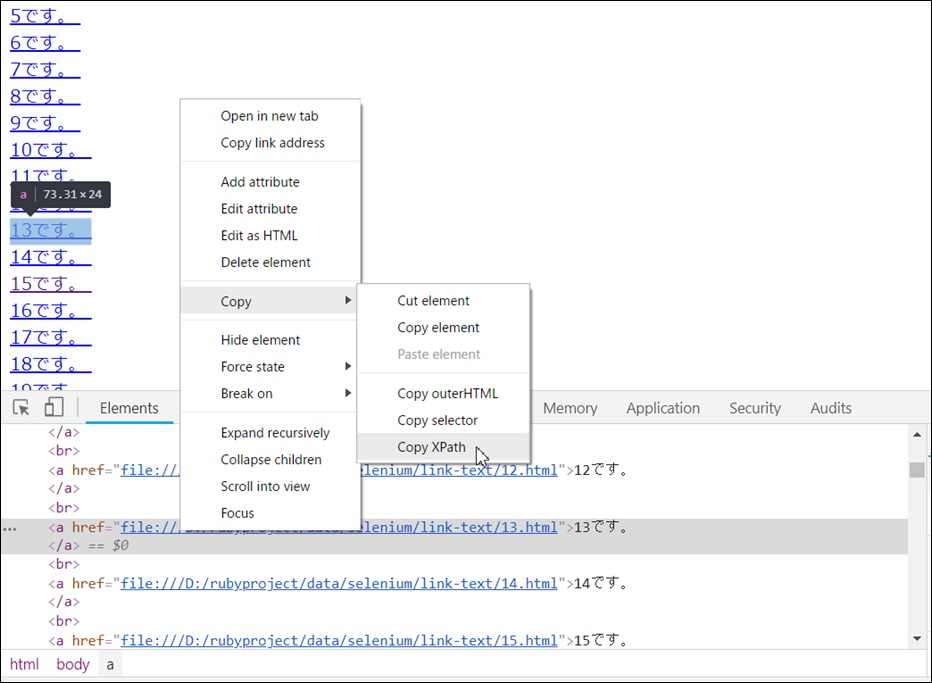
xpathの場合、Cromeの検証ツールで、右クリック→Copy→Copy Xpath で取得できる。
これを要素取得時に指定してあげれば、対象の要素が取得できる。
下の画像の要素の場合だと、
d.find_element(:xpath, '/html/body/a[13]')
と指定できる。
/html/body/a[13] の部分がxpath