








今日は、Seaborn そして機械学習について、学んだ。
もうすぐPython講座も終わりに近づいてきた。
早くスタートテストをクリアしたい。
■AIを学ぶ為の本格Python講座
PY23_Seaborn
PY24_機械学習とは
今日学んだこと
■PY23_Seaborn
Seaborn
Matplotlibと同じく、データを可視化するライブラリ
統計データ等をmatplotlibより簡単にきれいなデザインで表現できる。
ペアプロット
各要素について、どの要素とどの要素の関係が強いか
視覚的に確認することができる。
import matplotlib.pyplot as plt
dimport seaborn as sns
plt.style.use('seaborn')
iris=sns.load_dataset("iris")
g=sns.PairGrid(iris, hue="species")
g.map(plt.scatter);
Seabornはグラフを作るとき、matplotlibを使っているので
Matplotlibのスタイルを使える。
背景を黒にする。
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('dark_background')
iris=sns.load_dataset("iris")
g=sns.PairGrid(iris, hue="species")
g.map(plt.scatter);

使用例 ボストン住宅価格データセット
ボストン住宅価格データセット(住宅価格を予想するデータセット)
を使って、実際に分析をしてみる。
(参考)
https://atmarkit.itmedia.co.jp/ait/articles/2006/24/news033.html
import pandas as pd
from sklearn.datasets import load_boston
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn')
dataset=load_boston()
df=pd.DataFrame(dataset.data,columns=dataset.feature_names)
df['MEDV']=dataset.target
df

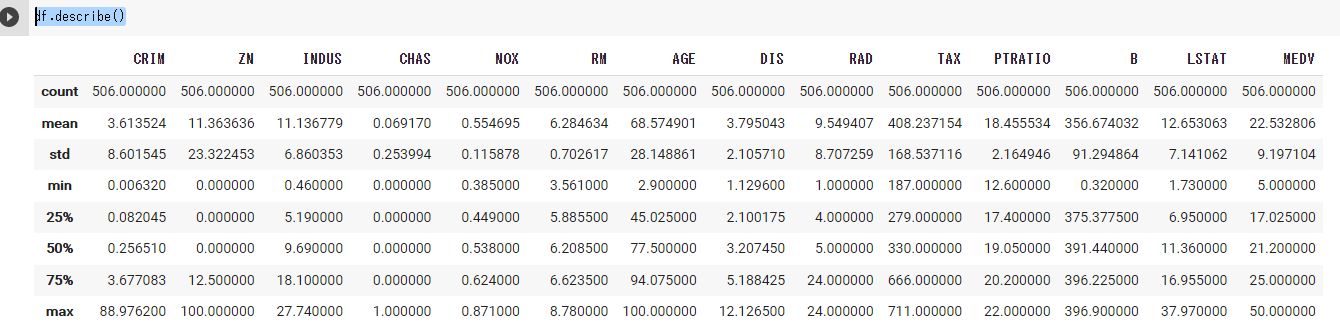
df.describe()
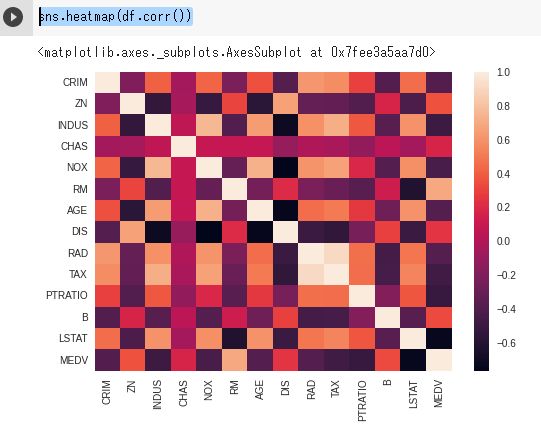
PandasのDataframeにあるcoor()メソッドは
各値の相関を調べられる。
その情報をheatmapに渡すと、視覚的に相関関係が分かる。
黒に近いほど、相関関係がない。
sns.heatmap(df.corr())
ペアプロットを使って、値の関係を調べることができる。
sns.pairplot(df[['RM','LSTAT','MEDV']])
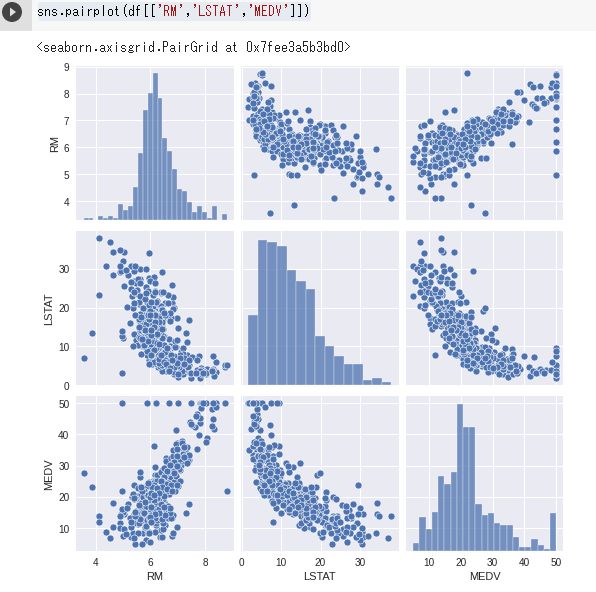
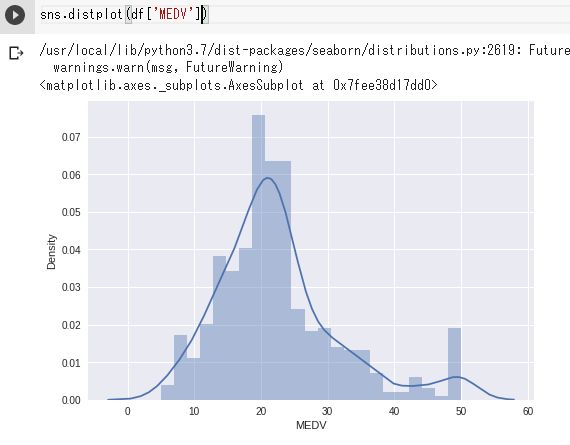
Seabornのdistplot()関数で、ヒストグラムと密度関数を得られる。
sns.distplot(df['MEDV'])
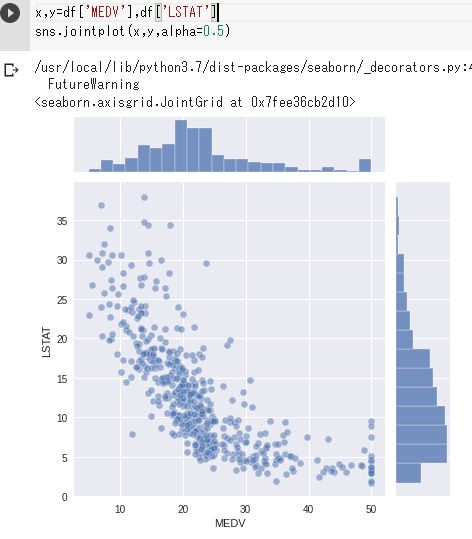
Seabornのjointplot()関数で、MEDVとLSTATの2つの値の分布の相関を確認できる。
x,y=df['MEDV'],df['LSTAT']
sns.jointplot(x,y,alpha=0.5)
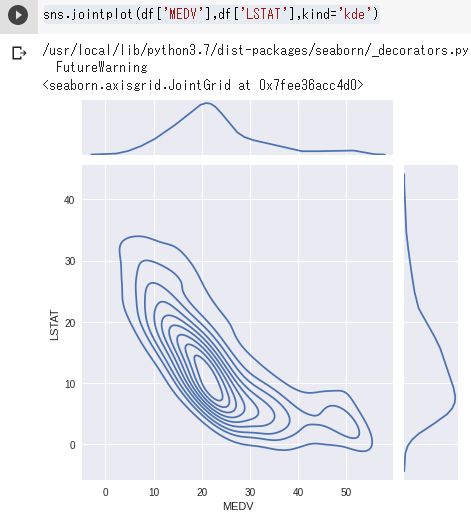
jointpot()には別の表示形式もある。
sns.jointplot(df['MEDV'],df['LSTAT'],kind='kde')
機械学習とは
機械学習の技術は大きく2つ
1.アルゴリズム(計算式)による機械学習
サイキットラーン
比較的データが少なくて、シンプルな構造のもの
統計データ、観測データを扱うのが得意
2.深層学習(ディープラーニング)
たくさんのデータが必要
センサーで集めた情報など大量のデータを扱うのが得意
機械学習と深層学習の比較
学習に必要なデータ・学習時間(計算量) ⇒ 機械学習<ディープラーニング
解ける問題の複雑さ ⇒ 機械学習<ディープラーニング
学習結果の説明性 ⇒ 機械学習〇 ディープラーニング×
機械学習と深層学習にはメリット、デメリットがあるので使い分けることが重要。
音声、画像、動画などのデータを扱う ⇒ 深層学習
表計算ソフトで扱うようなデータを扱う ⇒ 機械学習
scikit-learnは機械学習アルゴリズムを扱うライブラリ。
エクセルなどの表計算ソフトで扱うようなデータ、日々の売上、
実験結果、統計データの分析 に便利に使える。
学習と推論
機械学習は既知のデータから学習で、未知のデータに対して人間の役に立つデータを得ることを目指す。
なので、学習用のデータを準備しないといけない。
学習用のデータは、いろいろ工夫して集めたり、作ったりしている。
身近なところでは
・コンビニに蓄積されるデータ
・いろんな調査などのアンケート
・写真に写っているものに人間がラベルをつける。
がある。
データが出来たら、機械学習モデルを使えるようにするため、
1.学習
2.推論
という作業を行う。
この2つで実際に集めたデータをもとに機械学習モデルを習得して、未知のデータから
役に立つデータを推測する。
学習
集めたデータを用いて機械学習モデルに勉強させる。
その勉強の時間は、機械学習なのか深層学習なのかで
かかる時間が大きく変わる。
機械学習は比較的短時間で学習が終わるけど、深層学習は
たいへん。
深層学習は専用のコンピュータ等で学習する場合がほとんど。
深層学習を行うためのクラウドサービスもある。
推論
学習した機械学習モデルを使って、未知のデータより役に立つデータを出力させる。
教師あり学習・教師なし学習・強化学習
学習の種類は大きく三つ。
1.教師あり学習
データとそのデータに対する答えを人間が用意する。
2.教師なし学習
データに対する答えを用意しない。
データにある特徴を自力で見つけ出す。
1.クラスタリング
2.主成分分析
3.データの生成
クラスタリング
似たデータをグループに分けること
主成分分析
たくさんの情報から、特徴的な情報を分析し、ざっくりと説明する。
いろんなコーヒーのデータ(産地、作り方、味、などなど)から、
このコーヒーは飲みやすいと判断するなど。
データの生成
与えられた画像等の情報から、その特徴に近い画像を生成する。
猫の絵を大量に学習させ、猫の絵を描かすなど。
3.強化学習
学習データを用いない。
学習データの代わりに、目標を示し、その目標に近づくように
機械学習モデルが自力で学習していく方法。
囲碁や将棋などで有名。
機械学習のアルゴリズムは主に2つ
1.回帰
与えられたデータから別の値を推測するもの
2.分類
データをいくつかの種別に分ける。
有名なアルゴリズム
ナイーブベイズ
線形回帰
決定木
サポートベクタ―マシン(SVM)
ニューラルネットワーク
勉強時間
今日: 1.0時間
総勉強時間: 36時間
お得キャンペーンの紹介
ラビットチャレンジの
Amazonギフト券「5,000円」プレゼントキャンペーンのお知らせ
申込時に、以下コードを使えば、入会金が5000円引かれるようです。
また、紹介した僕にも5000円のAmazonギフト券が送られるようです。
お得なので、よかったら申込時お使いください。
紹介コード:friend0019697
※本キャンペーンの期間は、 2021年9月15日~10月31日 です。
「お友達紹介キャンペーン」特設ページ:
https://ai99